
课程介绍

Andrew Ng(吴恩达)在2012年推出的『机器学习』课程已经收获了超过 480 万学习者。2022年课程团队对其进行更新升级,广泛地介绍了现代机器学习,包括监督学习(多线性回归、逻辑回归、神经网络和决策树)、无监督学习(聚类、降维、推荐系统),以及硅谷用于人工智能和机器学习创新的一些最佳实践(评估和调整模型,采用以数据为中心的方法来提高性能等)。
课程学习结束时,学习者将掌握关键概念并获得实用知识,以快速有效地将机器学习应用于具有挑战性的现实问题。如果希望进入 AI 领域或在机器学习领域建立职业生涯,那么这门新版本的『机器学习专项课程』会是非常棒的选择!
课程讲师为Andrew Ng(吴恩达),曾在斯坦福大学领导过重要研究,并在 Google Brain、百度和 Landing.AI 开展了开创性工作,以推动 AI 领域的发展。
课程主题
本课程是 Stanford CS229 的内容拓展版,由吴恩达教授讲授。课程官网发布了课程主题,ShowMeAI 对其进行了翻译。
- Supervised Machine Learning: Regression and Classification(有监督机器学习:回归和分类)
- Introduction to Machine Learning(机器学习概论)
- Regression with multiple input variables(多输入变量回归)
- Classification(分类)
- Advanced Learning Algorithms(前沿学习算法)
- Neural Networks(神经网络)
- Neural network training(神经网络训练)
- Advice for applying machine learning(机器学习的实战建议)
- Decision trees(决策树)
- Unsupervised Learning, Recommenders, Reinforcement Learning(无监督学习 / 推荐 / 强化学习)
- Unsupervised learning(无监督学习)
- Recommender systems(推荐系统)
- Reinforcement learning(强化学习)
课程资料 | 下载
 |
扫描上方图片二维码,关注公众号并回复关键字 🎯『AndrewNG-ML』,就可以获取整理完整的资料合辑啦!当然也可以点击 🎯 这里 查看更多课程的资料获取方式!
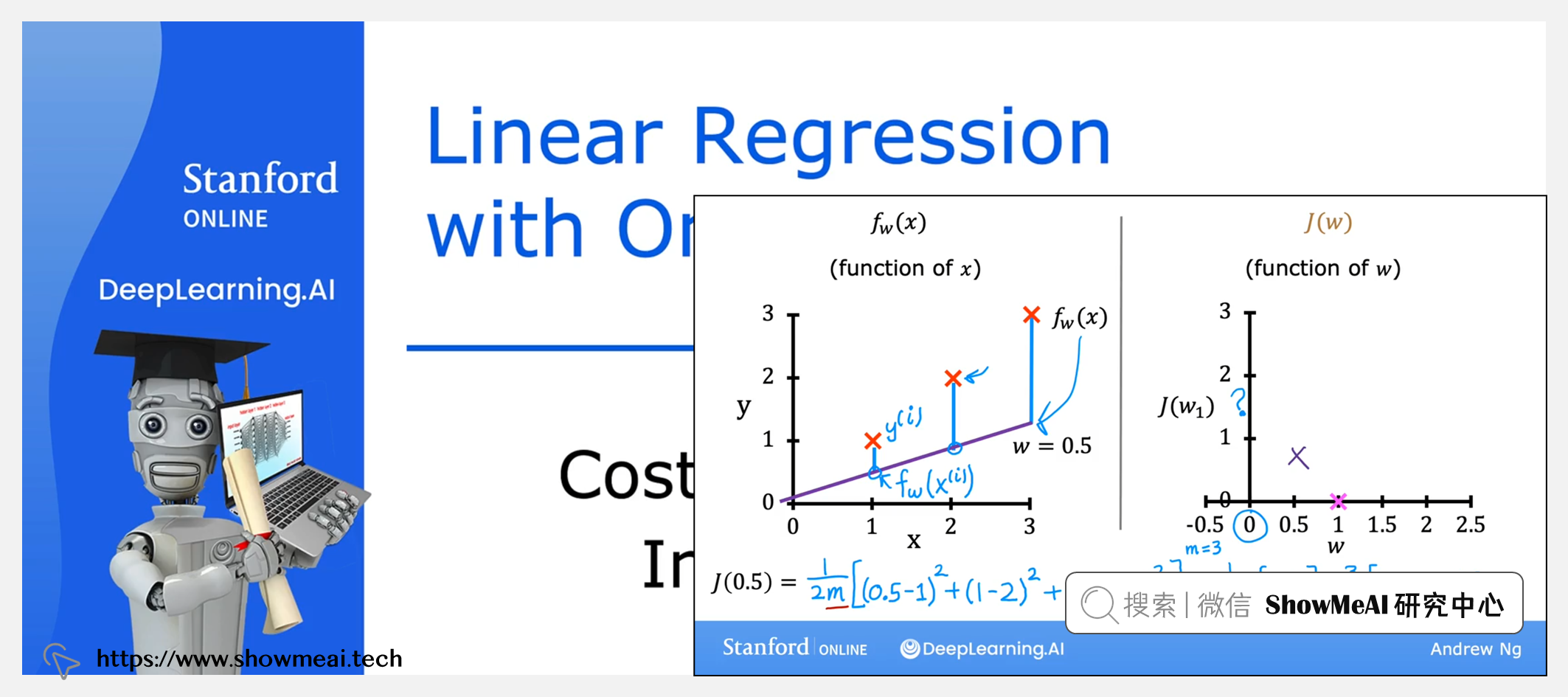
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包:
- 📚 课件(PPT格式)。包括3门课程的全部课件高清版。
- 📚 作业(.ipynb格式)。课程布置的全部作业。
- 📚 课程代码(.ipynb格式)。课程终于使用Python进行讲解啦~
课程视频 | B站
ShowMeAI 将视频上传至B站,并增加了中英双语字幕,以提供更加友好的学习体验。点击页面视频,可以进行预览。推荐前往 👆 B站 观看完整课程视频哦!
本门课程,ShowMeAI 将部分章节进行了切分,按照主题形成更短小的视频片段,便于按照标题进行更快速的检索。切分后的视频清单列写在这里:
| 第一课 | 第二课 | 第三课 |
| 🎯 第一周 | 🎯 第一周 | 🎯 第一周 |
| 1.1 欢迎参加《机器学习》课程 | 1.1 欢迎 | 1.1 欢迎来到第三课 |
| 1.2 机器学习应用 | 1.2 神经元和大脑 | 2.1 什么是聚类 |
| 2.1 机器学习定义 | 1.3 需求预测 | 2.2 K-means直观理解 |
| 2.2 监督学习-part-1 | 1.4 举例-图像感知 | 2.3 K-means算法 |
| 2.3 监督学习-part-2 | 2.1 神经网络中的网络层 | 2.4 优化目标 |
| 2.4 无监督学习-part-1 | 2.2 更复杂的神经网络 | 2.5 初始化 K-means |
| 2.5 无监督学习-part-2 | 2.3 神经网络前向传播 | 2.6 选择聚类数量 |
| 2.6 Jupyter notebooks | 3.1 如何用代码实现推理 | 3.1 发现异常事件 |
| 3.1 线性回归模型-part-1 | 3.2 Tensorflow中数据形式 | 3.2 高斯正态分布 |
| 3.2 线性回归模型-part-2 | 3.3 搭建一个神经网络 | 3.3 异常检测算法 |
| 3.3 代价函数公式 | 4.1 单个网络层上的前向传播 | 3.4 开发与评估异常检测系统 |
| 3.4 理解代价函数 | 4.2 前向传播的一般实现 | 3.5 异常检测与监督学习对比 |
| 3.5 可视化代价函数 | 5.1 强人工智能 | 3.6 选择使用什么特征 |
| 3.6 可视化举例 | 6.1 神经网络为何如此高效 | 🎯 第二周 |
| 4.1 梯度下降 | 6.2 矩阵乘法 | 1.1 提出建议 |
| 4.2 梯度下降的实现 | 6.3 矩阵乘法规则 | 1.2 使用每个特征 |
| 4.3 理解梯度下降 | 6.4 矩阵乘法代码 | 1.3 协同过滤算法 |
| 4.4 学习率 | 🎯 第二周 | 1.4 二进制标签 |
| 4.5 用于线性回归的梯度下降 | 1.1 Tensorflow实现 | 2.1 均值归一化 |
| 4.6 运行梯度下降 | 1.2 模型训练细节 | 2.2 协同过滤TensorFlow实现 |
| 🎯 第二周 | 2.1 Sigmoid激活函数的替代方案 | 2.3 寻找相关特征 |
| 1.1 多维特征 | 2.2 如何选择激活函数 | 3.1 协同过滤与基于内容过滤对比 |
| 1.2 向量化-part-1 | 2.3 为什么模型需要激活函数 | 3.2 基于内容过滤的深度学习方法 |
| 1.3 向量化-part-2 | 3.1 多分类问题 | 3.3 从大型目录中推荐 |
| 1.4 用于多元线性回归的梯度下降法 | 3.2 Softmax | 3.4 推荐系统中的伦理 |
| 2.1 特征缩放-part-1 | 3.3 神经网络的Softmax输出 | 3.5 基于内容过滤的TensorFlow实现 |
| 2.2 特征缩放-part-2 | 3.4 Softmax的改进实现 | 🎯 第三周 |
| 2.3 判断梯度下降是否收敛 | 3.5 多个输出的分类 | 1.1 什么是强化学习 |
| 2.4 如何设置学习率 | 4.1 高级优化方法 | 1.2 示例:火星探测器 |
| 2.5 特征工程 | 4.2 其他的网络层类型 | 1.3 强化学习的回报 |
| 2.6 多项式回归 | 🎯 第三周 | 1.4 决策:强化学习中的策略 |
| 🎯 第三周 | 1.1 决定下一步做什么 | 1.5 审查关键概念 |
| 1.1 动机与目的 | 1.2 模型评估 | 2.1 状态-动作价值函数定义 |
| 1.2 逻辑回归 | 1.3 模型选择&交叉验证测试集的训练方法 | 2.2 状态-动作价值函数示例 |
| 1.3 决策边界 | 2.1 通过偏差与方法进行诊断 | 2.3 贝尔曼方程 |
| 2.1 逻辑回归中的代价函数 | 2.2 正则化、偏差、方差 | 2.4 random stochastic environment(可选) |
| 2.2 简化逻辑回归代价函数 | 2.3 制定一个用于性能评估的基准 | 3.1 示例:连续状态空间应用 |
| 3.1 实现梯度下降 | 2.4 学习曲线 | 3.2 登月器 |
| 4.1 过拟合问题 | 2.5 (修订)决定下一步做什么 | 3.3 学习状态值函数 |
| 4.2 解决过拟合 | 2.6 方差与偏差 | 3.4 算法改进:改进的神经网络架构 |
| 4.3 正则化 | 3.1 机器学习开发的迭代 | 3.5 算法改进:ε-贪婪策略 |
| 4.4 用于线性回归的正则方法 | 3.2 误差分析 | 3.6 算法改进:小批量和软更新(可选) |
| 4.5 用于逻辑回归的正则方法 | 3.3 添加更多数据 | 3.7 强化学习的状态 |
| 3.4 迁移学习-使用其他任务中的数据 | 3.8 课程总结和致谢 | |
| 3.5 机器学习项目的完整周期 | ||
| 3.6 公平、偏见与伦理 | ||
| 4.1 倾斜数据集的误差指标 | ||
| 4.2 精确率与召回率的权衡 | ||
| 🎯 第四周 | ||
| 1.1 决策树模型 | ||
| 1.2 学习过程 | ||
| 2.1 纯度 | ||
| 2.2 选择拆分信息增益 | ||
| 2.3 整合 | ||
| 2.4 独热编码One-hot | ||
| 2.5 连续有价值的功能 | ||
| 2.6 回归树 | ||
| 3.1 使用多个决策树 | ||
| 3.2 有放回抽样 | ||
| 3.3 随机森林 | ||
| 3.4 XGBoost | ||
| 3.5 何时使用决策树 |
更多技术与课程清单 | 点击查看详细课程
