
课程介绍

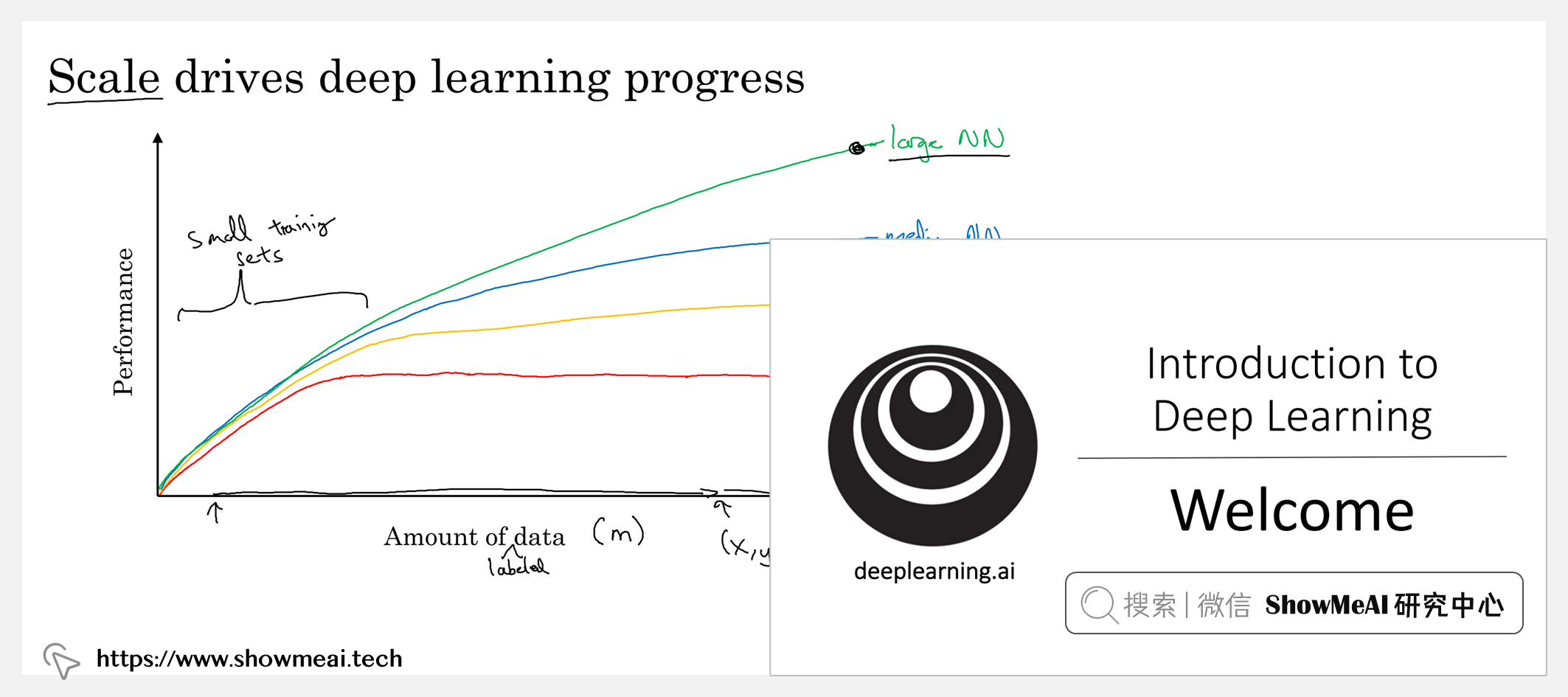
人工智能正在改变许多行业。本门课程可以帮助学习者了解深度学习的基础知识与挑战,并为参与前沿 AI 技术的开发做好准备,是非常好的入门学习选择。
本门课程可以帮助学习者掌握知识和技能,并邀请工业界与学术界的深度学习专家为大家提供职业发展建议,提供一条迈向 AI 世界的清晰途径。
在本课程中,学习者将构建和训练神经网络架构,例如卷积神经网络、循环神经网络、LSTM、Transformers,并学习如何使用 Dropout、BatchNorm、Xavier/He 初始化等策略进行优化。
此外,还将使用 Python 和 TensorFlow 掌握理论概念及其行业应用,并处理语音识别、音乐合成、聊天机器人、机器翻译、自然语言处理等现实案例。
吴恩达 Andrew Ng,斯坦福大学计算机科学教授,前百度副总裁、首席科学家,Google Brain项目的发起人和领导者。
课程主题
课程包含五个重要的课程板块:
- Neural Networks and Deep Learning(神经网络和深度学习)
- Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization(改善深层神经网络:超参数调优,正则化和优化)
- Structuring your Machine Learning project(构建机器学习项目)
- Convolutional Neural Networks(卷积神经网络)
- Natural Language Processing: Building sequence models(自然语言处理)
深度学习教程 | 吴恩达专项课程 全套笔记解读
| 深度学习教程 | 章节名称与链接 | 章节图 |
| 深度学习教程(1) | 深度学习概论 |  |
| 深度学习教程(2) | 神经网络基础 |  |
| 深度学习教程(3) | 浅层神经网络 |  |
| 深度学习教程(4) | 深层神经网络 |  |
| 深度学习教程(5) | 深度学习的实用层面 |  |
| 深度学习教程(6) | 神经网络优化算法 |  |
| 深度学习教程(7) | 网络优化:超参数调优、正则化、批归一化和程序框架 |  |
| 深度学习教程(8) | AI应用实践策略(上) |  |
| 深度学习教程(9) | AI应用实践策略(下) |  |
| 深度学习教程(10) | 卷积神经网络解读 |  |
| 深度学习教程(11) | 经典CNN网络实例详解 |  |
| 深度学习教程(12) | CNN应用:目标检测 |  |
| 深度学习教程(13) | CNN应用:人脸识别和神经风格转换 |  |
| 深度学习教程(14) | 序列模型与RNN网络 |  |
| 深度学习教程(15) | 自然语言处理与词嵌入 |  |
| 深度学习教程(16) | Seq2seq序列模型和注意力机制 |  |
课程资料 | 下载
 |
扫描上方图片二维码,关注公众号并回复关键字 🎯『AndrewNG-DL』,就可以获取整理完整的资料合辑啦!当然也可以点击 🎯 这里 查看更多课程的资料获取方式!
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包:
- 📚 课件 / Slides(PDF)。
- 📚 作业与答案 / Assignments and Solutions(.ipynb)。收集整理了两个版本的作业与答案。
- 📚 Deep Learning / 速查表(.ipynb)。
课程视频 | 网易云课堂
本门课程,ShowMeAI 按照主题进行了整理。可以使用页面『Ctrl+F』对需要检索的内容进行快速定位。切分后的视频清单列写在这里:
第1门-神经网络和深度学习
| 编号 | 课时内容 |
| P1 | 【第一周 深度学习概论】1.1 欢迎 |
| P2 | 1.2 什么是神经网络? |
| P3 | 1.3 用神经网络进行监督学习 |
| P4 | 1.4 为什么深度学习会兴起? |
| P5 | 1.5 关于这门课 |
| P6 | 1.6 课程资源 |
| P7 | 【第二周 神经网络基础】2.1 二分分类 |
| P8 | 2.2 logistic 回归 |
| P9 | – |
| P10 | 2.4 梯度下降法 |
| P11 | 2.5 导数 |
| P12 | 2.6 更多导数的例子 |
| P13 | 2.7 计算图 |
| P14 | 2.8 计算图的导数计算 |
| P15 | 2.9 logistic 回归中的梯度下降法 |
| P16 | 2.10 m 个样本的梯度下降 |
| P17 | 2.11 向量化 |
| P18 | 2.12 向量化的更多例子 |
| P19 | 2.13 向量化 logistic 回归 |
| P20 | 2.14 向量化 logistic 回归的梯度输出 |
| P21 | 2.15 Python 中的广播 |
| P22 | 2.16 关于 python _ numpy 向量的说明 |
| P23 | 2.17 Jupyter Ipython 笔记本的快速指南 |
| P24 | 2.18 (选修)logistic 损失函数的解释 |
| P25 | 【第三周 浅层神经网络】3.1 神经网络概览 |
| P26 | 3.2 神经网络表示 |
| P27 | 3.3 计算神经网络的输出 |
| P28 | 3.4 多个例子中的向量化 |
| P29 | 3.5 向量化实现的解释 |
| P30 | 3.6 激活函数 |
| P31 | 3.7 为什么需要非线性激活函数? |
| P32 | 3.8 激活函数的导数 |
| P33 | 3.9 神经网络的梯度下降法 |
| P34 | 3.10 (选修)直观理解反向传播 |
| P35 | 3.11 随机初始化 |
| P36 | 【第四周 深层神经网络】4.1 深层神经网络 |
| P37 | 4.2 深层网络中的前向传播 |
| P38 | 4.3 核对矩阵的维数 |
| P39 | 4.4 为什么使用深层表示 |
| P40 | 4.5 搭建深层神经网络块 |
| P41 | 4.6 前向和反向传播 |
| P42 | 4.7 参数 VS 超参数 |
| P43 | 4.8 这和大脑有什么关系? |
| P44 | 【人工智能行业大师访谈】1. 吴恩达采访 Geoffrey Hinton |
| P45 | 【人工智能行业大师访谈】2. 吴恩达采访 Pieter Abbeel |
| P46 | 【人工智能行业大师访谈】3. 吴恩达采访 Ian Goodfellow |
第2门-改善深层神经网络
| 编号 | 课时内容 |
| P1 | 【第一周 深度学习的实用层面】1.1 训练_开发_测试集 |
| P2 | 1.2 偏差_方差 |
| P3 | 1.3 机器学习基础 |
| P4 | 1.4 正则化 |
| P5 | 1.5 为什么正则化可以减少过拟合? |
| P6 | 1.6 Dropout 正则化 |
| P7 | 1.7 理解 Dropout |
| P8 | 1.8 其他正则化方法 |
| P9 | 1.9 归一化输入 |
| P10 | 1.10 梯度消失与梯度爆炸 |
| P11 | 1.11 神经网络的权重初始化 |
| P12 | 1.12 梯度的数值逼近 |
| P13 | 1.13 梯度检验 |
| P14 | 1.14 关于梯度检验实现的注记 |
| P15 | 【第二周 优化算法】2.1 Mini-batch 梯度下降法 |
| P16 | 2.2 理解 mini-batch 梯度下降法 |
| P17 | 2.3 指数加权平均 |
| P18 | 2.4 理解指数加权平均 |
| P19 | 2.5 指数加权平均的偏差修正 |
| P20 | 2.6 动量梯度下降法 |
| P21 | 2.7 RMSprop |
| P22 | 2.8 Adam 优化算法 |
| P23 | 2.9 学习率衰减 |
| P24 | 2.10 局部最优的问题 |
| P25 | 【第三周 超参数调试、Batch正则化和程序框架】3.1 调试处理 |
| P26 | 3.2 为超参数选择合适的范围 |
| P27 | 3.3 超参数训练的实践:Pandas VS Caviar |
| P28 | 3.4 正则化网络的激活函数 |
| P29 | 3.5 将 Batch Norm 拟合进神经网络 |
| P30 | 3.6 Batch Norm 为什么奏效? |
| P31 | 3.7 测试时的 Batch Norm |
| P32 | 3.8 Softmax 回归 |
| P33 | 3.9 训练一个 Softmax 分类器 |
| P34 | 3.10 深度学习框架 |
| P35 | 3.11 TensorFlow |
| P36 | 【人工智能行业大师访谈】1. 吴恩达采访 Yoshua Bengio |
| P37 | 【人工智能行业大师访谈】2. 吴恩达采访 林元庆 |
第3门-结构化机器学习
| 编号 | 课时内容 |
| P1 | 【第一周 机器学习(ML)策略(1)】1.1 为什么是 ML 策略 |
| P2 | 1.2 正交化 |
| P3 | 1.3 单一数字评估指标 |
| P4 | 1.4 满足和优化指标 |
| P5 | 1.5 训练_开发_测试集划分 |
| P6 | 1.6 开发集合测试集的大小 |
| P7 | 1.7 什么时候该改变开发 测试集和指标 |
| P8 | 1.8 为什么是人的表现 |
| P9 | 1.9 可避免偏差 |
| P10 | 1.10 理解人的表现 |
| P11 | 1.11 超过人的表现 |
| P12 | 1.12 改善你的模型的表现 |
| P13 | 【第二周 机器学习(ML)策略(2)】2.1 进行误差分析 |
| P14 | 2.2 清除标注错误的数据 |
| P15 | 2.3 快速搭建你的第一个系统,并进行迭代 |
| P16 | 2.4 在不同的划分上进行训练并测试 |
| P17 | 2.5 不匹配数据划分的偏差和方差 |
| P18 | 2.6 定位数据不匹配 |
| P19 | 2.7 迁移学习 |
| P20 | 2.8 多任务学习 |
| P21 | 2.9 什么是端到端的深度学习 |
| P22 | 2.10 是否要使用端到端的深度学习 |
| P23 | 【人工智能行业大师访谈】1. 采访 Andrej Karpathy |
| P24 | 【人工智能行业大师访谈】2. 采访 Ruslan Salakhutdinov |
第4门-卷积神经网络
| 编号 | 课时内容 |
| P1 | 【第一周 卷积神经网络】1.1 计算机视觉 |
| P2 | 1.2 边缘检测示例 |
| P3 | 1.3 更多边缘检测内容 |
| P4 | 1.4 Padding |
| P5 | 1.5 卷积步长 |
| P6 | 1.6 三维卷积 |
| P7 | 1.7 单层卷积网络 |
| P8 | 1.8 简单卷积网络示例 |
| P9 | 1.9 池化层 |
| P10 | 1.10 卷积神经网络示例 |
| P11 | 1.11 为什么使用卷积? |
| P12 | 【第二周 深度卷积网络:实例探究】2.1 为什么要进行实例探究? |
| P13 | 2.2 经典网络 |
| P14 | 2.3 残差网络 |
| P15 | 2.4 残差网络为什么有用? |
| P16 | 2.5 网络中的网络以及 1×1 卷积 |
| P17 | 2.6 谷歌 Inception 网络简介 |
| P18 | 2.7 Inception 网络 |
| P19 | 2.8 使用开源的实现方案 |
| P20 | 2.9 迁移学习 |
| P21 | 2.10 数据扩充 |
| P22 | 2.11 计算机视觉现状 |
| P23 | 【第三周 目标检测】3.1 目标定位 |
| P24 | 3.2 特征点检测 |
| P25 | 3.3 目标检测 |
| P26 | 3.4 卷积的滑动窗口实现 |
| P27 | 3.5 Bounding Box预测 |
| P28 | 3.6 交并比 |
| P29 | 3.7 非极大值抑制 |
| P30 | 3.8 Anchor Boxes |
| P31 | 3.9 YOLO 算法 |
| P32 | 3.10 候选区域 |
| P33 | 【第四周 特殊应用:人脸识别和神经风格转换】4.1 什么是人脸识别? |
| P34 | 4.2 One-Shot 学习 |
| P35 | 4.3 Siamese 网络 |
| P36 | 4.4 Triplet 损失 |
| P37 | 4.5 面部验证与二分类 |
| P38 | 4.6 什么是神经风格转换? |
| P39 | 4.7 什么是深度卷积网络? |
| P40 | 4.8 代价函数 |
| P41 | 4.9 内容代价函数 |
| P42 | 4.10 风格代价函数 |
| P43 | 4.11 一维到三维推广 |
第5门-序列数据建模
| 编号 | 课时内容 |
|---|---|
| P1 | 【第一周 循环序列模型】1.1为什么选择序列模型 |
| P2 | 1.2数学符号 |
| P3 | 1.3循环神经网络 |
| P4 | 1.4通过时间的方向传播 |
| P5 | 1.5不同类型的循环神经网络 |
| P6 | 1.6 语言模型和序列生成 |
| P7 | 1.7 对新序列采样 |
| P8 | 1.8带有神经网络的梯度消失 |
| P9 | 1.9 GRU 单元 |
| P10 | 1.10 长短期记忆(LSTM) |
| P11 | 1.11 双向神经网络 |
| P12 | 1.12 深层循环神经网络 |
| P13 | 【第二周 自然语言处理与词嵌入】2.1 词汇表征 |
| P14 | 2.2 使用词嵌入 |
| P15 | 2.3 词嵌入的特性 |
| P16 | 2.4 嵌入矩阵 |
| P17 | 2.5 学习词嵌入 |
| P18 | 2.6 Word2Vec |
| P19 | 2.7 负采样 |
| P20 | 2.8 GloVe 词向量 |
| P21 | 2.9 情绪分类 |
| P22 | 2.10 词嵌入除偏 |
| P23 | 【第三周 序列模型和注意力机制】3.1 基础模型 |
| P24 | 3.2 选择最可能的句子 |
| P25 | 3.3 定向搜索 |
| P26 | 3.4 改进定向搜索 |
| P27 | 3.5 定向搜索的误差分析 |
| P28 | 3.6 Bleu 得分(选修) |
| P29 | 3.7 注意力模型直观理解 |
| P30 | 3.8 注意力模型 |
| P31 | 3.9 语音辨识 |
| P32 | 3.10 触发字检测 |
| P33 | 3.11 结论和致谢 |
更多技术与课程清单 | 点击查看详细课程
