
课程介绍

Applied Deep Learning 是目前全网知识点覆盖最全的深度学习课程之一,需要两个学期的学习时长,主要面向研究生(也很适合有概率、统计学、数值线性代数和优化知识储备的本科生),目标是让学生熟悉行业中采用的最先进的深度学习技术。
课程对于从深度学习诞生至今的各领域(深度学习模型结构研究、自然语言处理、计算机视觉、强化学习、图神经网络)典型模型,都有逐步的展开和讲解。跟随课程的学习,我们可以看到研究界的创新和思考过程,模型的迭代和优化过程,对于深度学习的各类模型和典型应用,有全面充分的理解。
深度学习每隔几个月就会见证一场小型革命的领域,因此课程学生需要保持对新知识的渴望,并课程学习结束时能够编写干净的代码。
课程使用的编程语言是 Python。熟悉 TensorFlow 和 PyTorch 是加分项但不要求,但是愿意在课程中努力学习和使用这两个框架是非常重要的。
课程主题
课程官网发布了课程主题,ShowMeAI 对其进行了翻译。
- Training Deep Neural Networks(训练深度神经网络)
- Computer Vision(计算机视觉)
- Image Classification(图像分类)
- Image Transformation(图像变换)
- Object Detection(目标检测)
- Face Recognition and Detection(人脸识别与检测)
- Video(视频)
- 3D(3D)
- Natural Language Processing(自然语言处理)
- Multimodal Learning(多模式学习)
- Generative Networks(生成网络)
- Advanced Topics(进阶话题)
- Speech & Music(演讲与音乐)
- Reinforcement Learning(强化学习)
- Graph Neural Networks(图神经网络)
- Recommender Systems(推荐系统)
- Computational Biology(计算生物学)
课程资料 | 下载

扫描上方图片二维码,关注公众号并回复关键字 🎯『APPLY-DL』,就可以获取整理完整的资料合辑啦!当然也可以点击 🎯 这里 查看更多课程的资料获取方式!
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包:
- 📚 课件。PDF文件。覆盖所有视频章节。干货密度极高,每页课件都值得研究收藏~
课程视频 | B站
ShowMeAI 将视频上传至B站,并增加了中英双语字幕,以提供更加友好的学习体验。点击页面视频,可以进行预览。推荐前往 👆 B站 观看完整课程视频哦!
本门课程内容非常多!为方便大家检索(查找某主题的位置,请使用页面 Ctrl+F 关键字检索功能),依旧将完整清单放在这里:
| 课时编号 | 课时内容 |
|---|---|
| 第1.1讲 | 深度学习概述 |
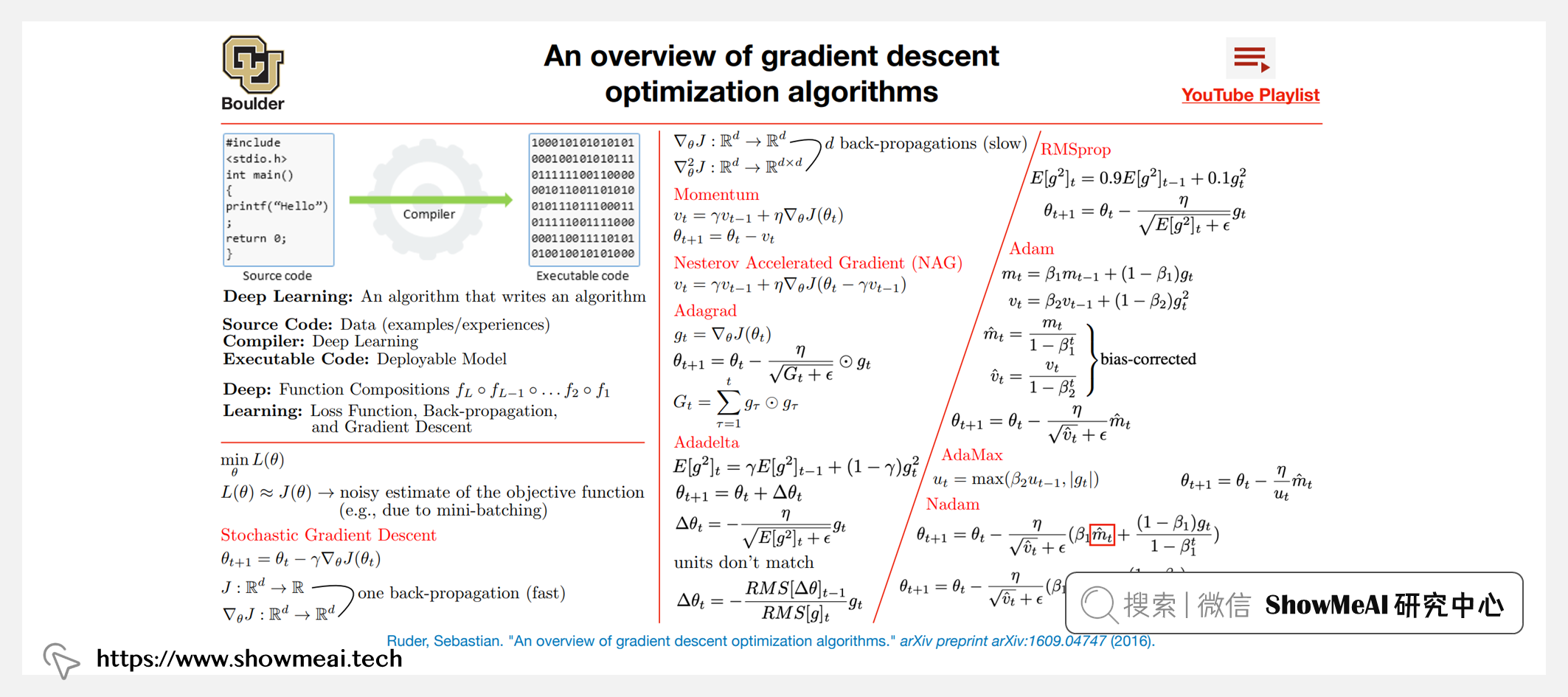
| 第1.2讲 | 梯度下降算法 |
| 第2.1讲 | 梯度下降算法 |
| 第2.2讲 | AlexNet |
| 第3.1讲 | 随机失活dropout |
| 第3.2讲 | Network in Network |
| 第4.1讲 | Network in Network |
| 第4.2讲 | VGG-16和VGG-19 |
| 第4.3讲 | GoogLeNet |
| 第5.1讲 | GoogLeNet |
| 第5.2讲 | 批标准化 |
| 第6.1讲 | 批标准化 |
| 第6.2讲 | Kaiming参数初始化 |
| 第7.1讲 | Kaiming参数初始化 |
| 第7.2讲 | Inception-V3 |
| 第8.1讲 | Inception-V3 |
| 第8.2讲 | resnet |
| 第9.1讲 | 恒等映射 |
| 第9.2讲 | 宽残差网络 |
| 第10.1讲 | ResNeXt |
| 第10.2讲 | DenseNet |
| 第10.3讲 | Inception-V4 |
| 第11.1讲 | 压缩与激活 |
| 第12.1讲 | Spatial Transformer Networks |
| 第13.1讲 | 胶囊网络 |
| 第14.1讲 | 小型神经网络 |
| 第14.2讲 | 知识蒸馏 |
| 第15.1讲 | 知识蒸馏 |
| 第15.2讲 | 深度压缩 |
| 第16.1讲 | 深度压缩 |
| 第17.1讲 | SqueezeNet |
| 第17.2讲 | XNOR网络 |
| 第18.1讲 | XNOR网络 |
| 第18.2讲 | MobileNets |
| 第19.1讲 | MobileNets |
| 第19.2讲 | Xception |
| 第19.3讲 | MobileNetV2 |
| 第19.4讲 | ShuffleNet |
| 第20.1讲 | NASNet |
| 第20.2讲 | AmoebaNet-A |
| 第21.1讲 | EfficientNet |
| 第21.2讲 | 对抗学习示例 |
| 第22.1讲 | 对抗学习示例 |
| 第22.2讲 | 快速梯度符号方法 |
| 第23.1讲 | Breaking Defensive蒸馏 |
| 第23.2讲 | 稳健优化 |
| 第24.1讲 | 稳健优化 |
| 第24.2讲 | 单像素攻击 |
| 第25.1讲 | 单像素攻击 |
| 第25.2讲 | CNN可视化与理解 |
| 第26.1讲 | LIME |
| 第26.2讲 | 类激活图 |
| 第27.1讲 | 类激活图 |
| 第27.2讲 | 有限样本表示性 |
| 第28.1讲 | 有限样本表示性 |
| 第28.2讲 | Grad-CAM |
| 第28.3讲 | 迁移学习 |
| 第29.1讲 | DeCAF |
| 第29.2讲 | 卷积神经网络特征解析 |
| 第29.3讲 | 全卷积网络 |
| 第30.1讲 | 全卷积网络 |
| 第30.2讲 | U-Net |
| 第30.3讲 | DeepLab |
| 第31.1讲 | DeepLab |
| 第31.2讲 | 扩张卷积 |
| 第32.1讲 | 扩张卷积 |
| 第32.2讲 | SegNet |
| 第32.3讲 | 金字塔场景解析网络 |
| 第32.4讲 | DeepLabv3+ |
| 第33.1讲 | 超分辨率卷积神经网络 |
| 第33.2讲 | Perceptual损失 |
| 第33.3讲 | 单图像超分辨率 |
| 第33.4讲 | 去噪卷积神经网络 |
| 第34.1讲 | 平均精度(mAP) |
| 第34.2讲 | R-CNN |
| 第35.1讲 | 空间金字塔池化 |
| 第35.2讲 | Fast R-CNN |
| 第36.1讲 | Faster R-CNN |
| 第36.2讲 | R-FCN |
| 第37.1讲 | 特征金字塔网络 |
| 第37.2讲 | Mask R-CNN |
| 第38.1讲 | OverFeat |
| 第38.2讲 | YOLO |
| 第39.1讲 | SSD |
| 第39.2讲 | YOLO9000 |
| 第40.1讲 | Focal Loss |
| 第40.2讲 | YOLOv3 |
| 第40.3讲 | 视频分类 |
| 第41.1讲 | 视频中的动作识别 |
| 第41.2讲 | 三维卷积网络 |
| 第41.3讲 | Inflated 3d ConvNet(I3D) |
| 第42.1讲 | 非局部神经网络 |
| 第42.2讲 | 组归一化 |
| 第43.1讲 | PointNet |
| 第43.2讲 | PointNet++ |
| 第43.3讲 | 动态图形卷积网络(DGCNN) |
| 第44.1讲 | Word2Vec |
| 第45.1讲 | Word2Vec |
| 第46.1讲 | Word2vec |
| 第46.2讲 | GloVe |
| 第47.1讲 | 子词模型 |
| 第48.1讲 | 递归深度模型 |
| 第48.2讲 | 用于句子分类的CNN |
| 第49.1讲 | 用于句子分类的CNN |
| 第49.2讲 | Doc2vec |
| 第49.3讲 | 基于CNNs的文本分类 |
| 第50.1讲 | FastText |
| 第50.2讲 | 层次注意力网络 |
| 第51.1讲 | 命名实体识别 |
| 第51.2讲 | ULMFIT |
| 第52.1讲 | 神经机器翻译 |
| 第52.2讲 | 序列到序列建模(seq2seq) |
| 第53.1讲 | 短语表征 |
| 第53.2讲 | Gated Recursive CNN |
| 第53.3讲 | 基于注意力的神经机器翻译 |
| 第54.1讲 | 基于注意力的神经机器翻译 |
| 第54.2讲 | 字节对编码(BPE) |
| 第55.1讲 | 谷歌神经机器翻译系统 |
| 第55.2讲 | 卷积序列到序列模型 |
| 第56.1讲 | Transformer |
| 第56.2讲 | Reformer |
| 第57.1讲 | ELMo |
| 第57.2讲 | GPT-1 |
| 第57.3讲 | BERT |
| 第58.1讲 | BERT |
| 第58.2讲 | GPT-2 |
| 第58.3讲 | ALBERT |
| 第58.4讲 | ALBERT |
| 第59.1讲 | Transformer-XL |
| 第59.2讲 | XLNet |
| 第60.1讲 | 跨语种语言模型 |
| 第60.2讲 | GPT-3 |
| 第60.3讲 | 视觉识别与描述 |
| 第61.1讲 | 视觉识别与描述 |
| 第61.2讲 | 看图说话 |
| 第61.3讲 | 视觉语义对齐 |
| 第62.1讲 | 视觉语义对齐 |
| 第62.2讲 | Show, Attend and Tell看图说话 |
| 第63.1讲 | Show, Attend and Tell看图说话 |
| 第63.2讲 | 层标准化 |
| 第63.3讲 | 视觉问答 |
| 第63.4讲 | DALL-E |
| 第64.1讲 | 变分自动编码器 |
| 第64.2讲 | 生成对抗网络 |
| 第64.3讲 | 条件GAN |
| 第65.1讲 | DCGANs |
| 第65.2讲 | Inception Score |
| 第65.3讲 | Vaes Versus GANs |
| 第66.1讲 | Inception Score |
| 第66.2讲 | InfoGAN |
| 第66.3讲 | 上下文编码器 |
| 第67.1讲 | 最小二乘GAN |
| 第67.2讲 | Pix2pix |
| 第67.3讲 | Cycle-Consistent GAN |
| 第67.4讲 | Wasserstein GAN |
| 第68.1讲 | Wasserstein GAN |
| 第68.2讲 | 基于GAN的单图像超分辨率变换 |
| 第68.3讲 | 梯度惩罚 |
| 第69.1讲 | 离散数据的GAN |
| 第69.2讲 | GAN的渐进学习 |
| 第69.3讲 | Frechet Inception Distance ( FID ) |
| 第70.1讲 | 谱归一化 |
| 第70.2讲 | Pix2pixHD |
| 第70.3讲 | BigGANs |
| 第71.1讲 | StyleGan |
| 第71.2讲 | 自注意力生成对抗网络 |
| 第71.3讲 | StarGAN |
| 第72.1讲 | Mel谱图与MFCCs |
| 第72.2讲 | CTC算法 |
| 第73.1讲 | 语音识别 |
| 第73.2讲 | GRU模型 |
| 第73.3讲 | 期望转录损失 |
| 第74.1讲 | CTC集束搜索 |
| 第74.2讲 | Deep Speech |
| 第74.3讲 | WaveNet |
| 第75.1讲 | WaveNet |
| 第75.2讲 | 长短时记忆 |
| 第75.3讲 | Deep Speech 2 |
| 第75.4讲 | SpecAugment |
| 第76.1讲 | Listen, Attend, and Spell |
| 第76.2讲 | Jasper & NovoGrad |
| 第76.3讲 | Wav2vec 2.0 |
| 第77.1讲 | 深度Q学习 |
| 第77.2讲 | 人体水平控制 |
| 第77.3讲 | 深确定性策略梯度 |
| 第78.1讲 | 深确定性策略梯度 |
| 第78.2讲 | 信赖域策略优化 |
| 第79.1讲 | 信赖域策略优化 |
| 第79.2讲 | AlphaGo |
| 第80.1讲 | 共轭梯度法 |
| 第80.2讲 | RL算法大全 |
| 第80.3讲 | A3C算法 |
| 第80.4讲 | 深度学习中的模型不确定性 |
| 第81.1讲 | 双Q学习 |
| 第81.2讲 | 自动驾驶汽车的端到端学习 |
| 第81.3讲 | 深层视觉运动策略 |
| 第82.1讲 | AlphaGo Zero |
| 第82.2讲 | AlphaZero |
| 第82.3讲 | 近端策略优化 |
| 第82.4讲 | Model-Agnostic Meta-Learning |
| 第83.1讲 | Model-Agnostic Meta-Learning |
| 第83.2讲 | Visual Serving |
| 第83.3讲 | Soft Actor-Critic算法 |
| 第84.1讲 | DeepWalk算法 |
| 第84.2讲 | LINE模型 |
| 第84.3讲 | node2vec |
| 第84.4讲 | 图卷积网络 |
| 第85.1讲 | 图卷积网络 |
| 第85.2讲 | 快速局部化光谱滤波 |
| 第85.3讲 | GraphsAGE |
| 第85.4讲 | 图注意力网络 |
| 第85.5讲 | 图同构网络 |
更多技术与课程清单 | 点击查看详细课程
