
课程介绍

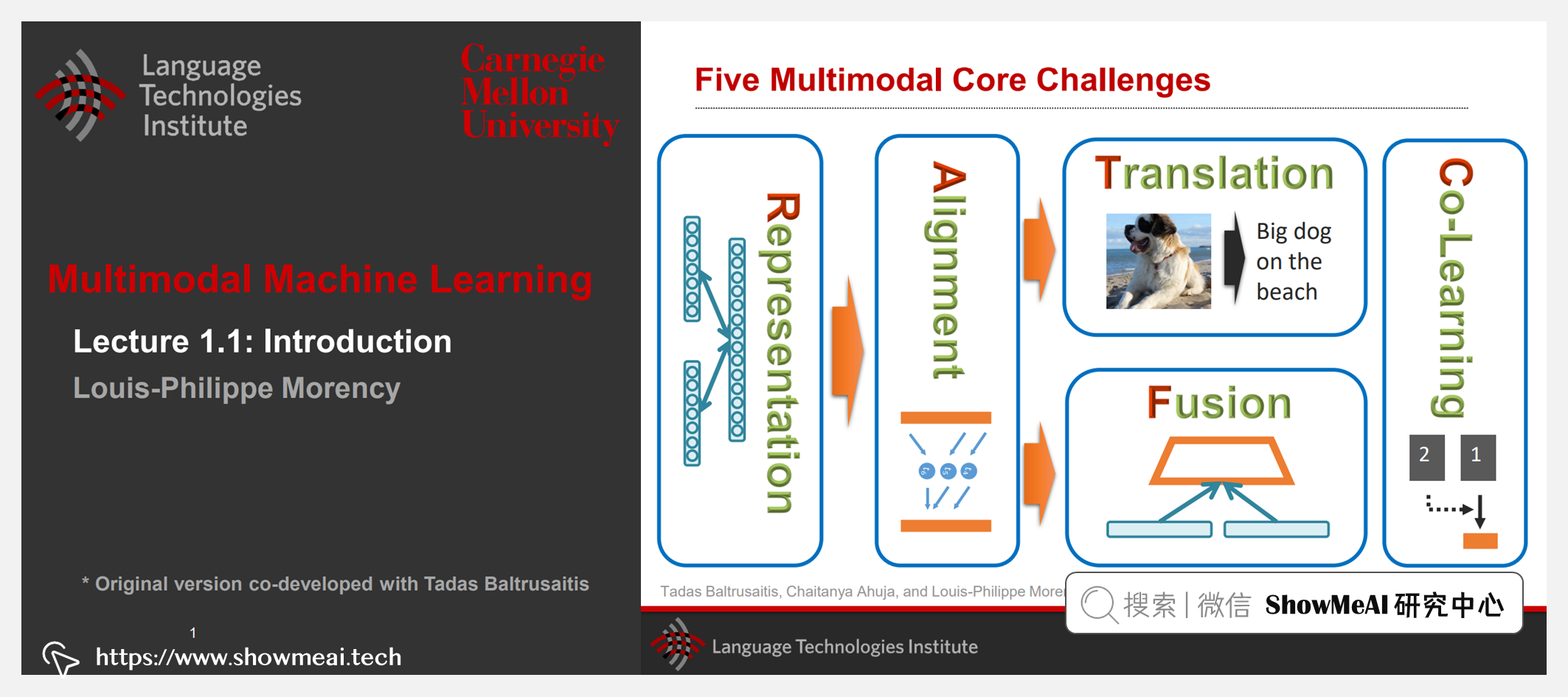
目前在工业界的实际应用场景中,有大量不同形态数据存在的场景,对这些数据联合应用与建模驱动业务,是研究界和工业界都异常关心的主题。多模式机器学习 (MMML) 是一个充满活力的多学科研究领域,它通过集成和建模多种交流模式(包括语言、声学和视觉信息)来解决人工智能的一些目标。
CMU 11-777 是全球顶校卡内基梅隆开设的AI专项课程,课程以多模态(MMML)为主题,讲解基本数学概念、文本与图像等多种数据形态联合应用&建模的前沿知识与方法,并回顾最近描述 MMML 的最先进的概率模型和计算算法的论文,并讨论当前和即将面临的挑战。通过本课程的学习,大家可以了解到目前前沿研究下对多模态处理的方法。
课程讲师 Louis-Philippe Morency,CMU 语言技术学院的终身教授,领导多模式通信和机器学习实验室 (MultiComp Lab),研究重点是建立计算基础使计算机能够分析、识别和预测社交互动中微妙的人类交流行为,核心就是应对多模态机器学习面临的技术挑战。
课程主题
本课程将介绍与多模态机器学习的主要概念,并将讨论近期的诸多应用。课程在官网发布了详细主题,ShowMeAI 对其进行了翻译。
- Multimodal applications and datasets(数据集)
- Basic concepts: neural networks(基本概念:神经网络)
- Basic concepts: network optimization(基本概念:优化)
- Visual unimodal representations(CNN 和视觉表示)
- Language unimodal representations(语言表示)
- Multimodal representation learning(多模态表示)
- Coordinated representations(协调表示)
- Multimodal alignment(多模式对齐)
- Alignment and representation(对齐和表示)
- Alignment and translation(对齐和平移 (映射))
- Probabilistic graphical models(生成模型)
- Discriminative graphical models(判别式图模型)
- Deep Generative Models(深度生成模型)
- Reinforcement learning(强化学习)
- Multimodal RL(多模态强化学习)
- Fusion and co-learning(融合、协同学习和新趋势)
- New research directions(新的研究方向)
- Embodied Language Grounding
- Multimodal Human-inspired Language Learning(受人类启发的多模态语言学习)
- Learning to connect text and images(连接文本和图像)
- Bias and fairness(偏见和公平)
课程资料 | 下载
 |
扫描上方图片二维码,关注公众号并回复关键字 🎯『11-777』,就可以获取整理完整的资料合辑啦!当然也可以点击 🎯 这里 查看更多课程的资料获取方式!
ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包:
- 📚 课件。PDF文件。覆盖Lecture 1~14 所有内容(说明:L6、L11、L13是break)
课程视频 | B站
ShowMeAI 将视频上传至B站,并增加了中英双语字幕,以提供更加友好的学习体验。点击页面视频,可以进行预览。推荐前往 👆 B站 观看完整课程视频哦!
本门课程,ShowMeAI 将部分章节进行了切分,按照主题形成更短小的视频片段,便于按照标题进行更快速的检索。切分后的视频清单列写在这里:
| 课时编号 | 课时内容 |
|---|---|
| 第1.1讲 | 介绍 |
| 第1.2讲 | 数据集 |
| 第2.1讲 | 基本概念 |
| 第2.2讲 | 基本概念:优化 |
| 第3.1讲 | CNN 和视觉表示 |
| 第3.2讲 | 语言表示,RNN |
| 第4.1讲 | 多模态表示 |
| 第4.2讲 | 协调表示 |
| 第5.1讲 | 多模式对齐 |
| 第5.2讲 | 对齐和表示 |
| 第7.1讲 | 对齐和平移 (映射) |
| 第7.2讲 | 生成模型 |
| 第8.1讲 | 判别式图模型 |
| 第8.2讲 | 深度生成模型 |
| 第9.1讲 | 强化学习 |
| 第9.2讲 | 多模态强化学习 |
| 第10.1讲 | 融合、协同学习和新趋势 |
| 第10.2讲 | 新的研究方向 |
更多技术与课程清单 | 点击查看详细课程
